DreamActor-M1
DiT-based human animation framework utilizing hybrid guidance for fine-grained holistic controllability, multi-scale adaptability, and long-term temporal coherence.
- • Imitates human behaviors from videos given a reference image
- • Produces highly expressive and realistic animations
- • Supports portraits to full-body motions
- • Maintains temporal consistency, identity preservation, and high fidelity
DreamActor-H1
AI-powered human-product video generation using Diffusion Transformers to create high-fidelity, realistic demonstration videos from a single image.
- • Preserves both human and product identity
- • Ensures natural motion and realistic interaction
- • Designed for e-commerce, advertising, and interactive media
- • Excels at human-product demonstration videos
Overview of DreamActor-M1
Recent advancements in image-based human animation have improved body and facial motion synthesis, but challenges remain in achieving fine-grained control, multi-scale adaptability, and long-term consistency. These limitations can affect the expressiveness and robustness of animations.
DreamActor-M1 Features:
- Motion guidance A hybrid control mechanism that combines implicit facial representations, 3D head spheres, and 3D body skeletons to ensure robust and expressive facial and body movements.
- Scale adaptability A progressive training strategy that incorporates multi-resolution data to manage various body poses and image scales (from portraits to full-body views).
- Appearance guidance Motion patterns from sequential frames and visual references help maintain long-term temporal coherence, particularly for unseen regions during complex motions.
Method Overview
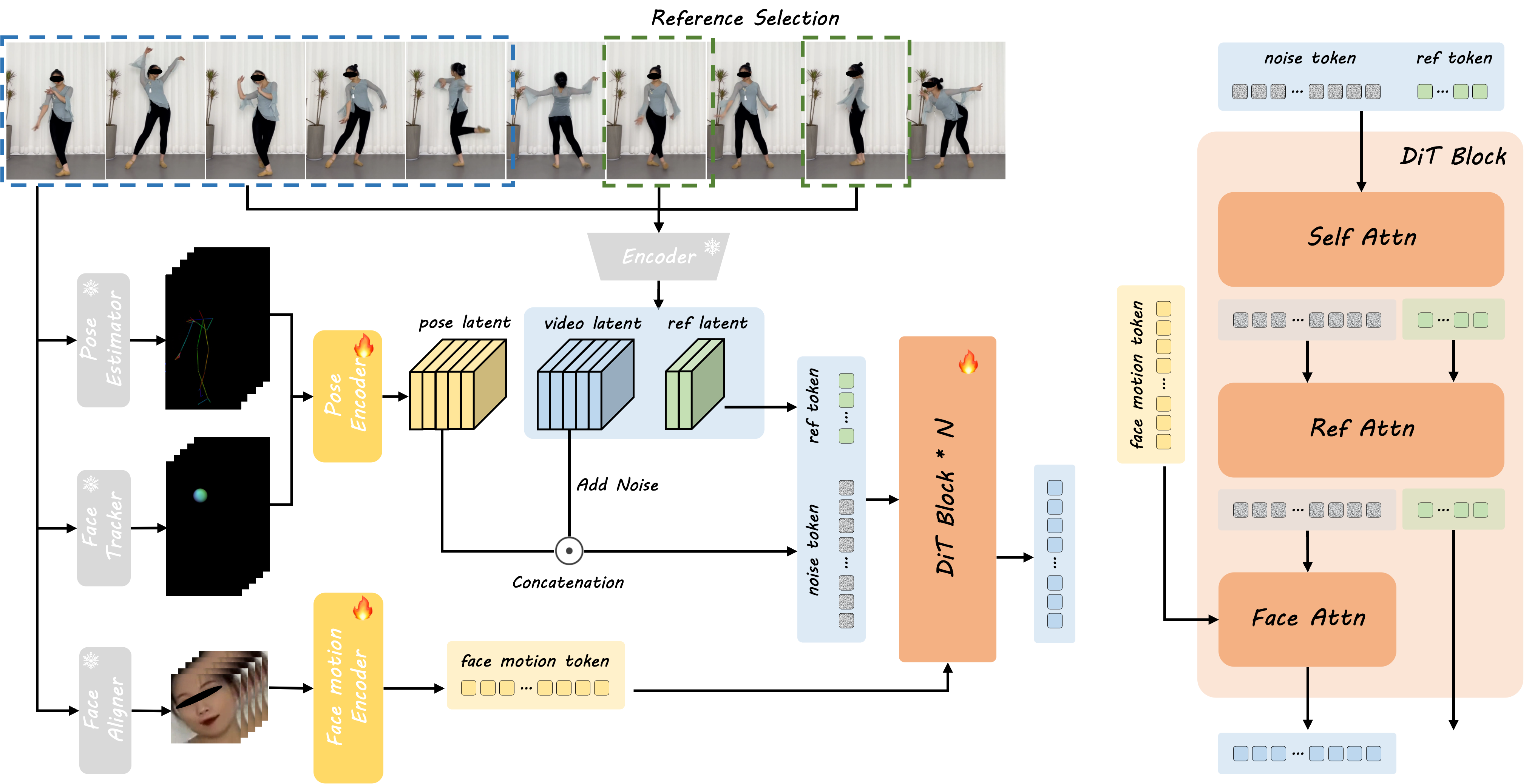
- 1Reference Image Processing The framework interpolates the start reference image and extracts body skeletons and head spheres from driving frames.
- 2Pose Encoding The extracted skeletal data is encoded into a pose latent vector using the pose encoder.
- 3Latent Combination The pose latent is combined with the noised video latent obtained by 3D VAE encoding.
- 4Facial Expression Encoding A separate face motion encoder captures implicit facial representations.
- 5Multi-Scale Training Reference images sampled from videos provide additional appearance details, ensuring realism and robustness.
- 6DiT Processing The DiT model refines the video latent using Face Attention, Self-Attention, and Reference Attention.
- 7Supervision & Refinement The denoised video latent is supervised against the encoded video latent, ensuring high-quality outputs.
Video Demonstration
Abstract
DreamActor-M1 is a diffusion transformer (DiT) based framework for human animation that addresses key limitations in existing methods. Our approach features three main innovations: (1) Hybrid motion guidance combining facial expressions, 3D head modeling, and body skeletons for precise control while preserving identity, (2) Multi-scale adaptation supporting everything from portraits to full-body animations through progressive training, and (3) Enhanced temporal coherence by integrating sequential motion patterns with visual references. Through extensive testing, DreamActor-M1 demonstrates superior performance in generating consistent, high-quality animations across different scales and scenarios.
Key Features
Diversity
Our method is robust to various character and motion styles.
Controllability and Robustness
- Extends to audio-driven facial animation, delivering lip-sync results in multiple languages.
- Complementary visual guidance ensures better temporal consistency, particularly for human poses not observed in the reference.
- Supports transferring only a part of the motion, such as facial expressions and head movements.
- Adapts shape-aware animations via bone length adjustment techniques.
- Supports generating results under different head pose directions.
Comparing to SOTA Methods
Our method generates results with fine-grained motions, identity preservation, temporal consistency and high fidelity.
Pose Transfer
Portrait Animation
LATEST UPDATES AI NEWS & INSIGHTS
Gambo AI Games: A Comprehensive Overview
Gambo is an AI-powered game development platform, known as the "world's first Game Vibe Coding Agent." It transforms creative ideas into playable game prototypes through natural language instructions, automatically generating all necessary game assets.
Meta SAM 3D: Open-Source Breakthrough for Generating 3D Models from a Single Image
Meta's latest SAM 3D can automatically segment objects from a single image and directly generate complete 3D models (including geometry and textures). Fast, accurate, and simple—a breakthrough in 3D content generation.
Google Antigravity Deep Dive: The "Agent-first Development Platform" in the Gemini 3 Era
On November 18, 2025, Google officially released Antigravity—a true Agent-first AI development platform / AI IDE. It's not just a "coding assistant," but an AI worker capable of automatically planning, executing, and verifying entire tasks.
Frequently Asked Questions
What is DreamActor-M1?
DreamActor-M1 is a diffusion transformer (DiT) based framework designed for holistic, expressive, and robust human image animation using hybrid guidance. It can generate realistic videos from a reference image, mimicking human behaviors from driving videos across various scales.
How Does DreamActor-M1 Work?
It uses a DiT model with hybrid control signals (implicit facial representations, 3D head spheres, 3D body skeletons) for motion guidance. A progressive training strategy handles different scales, and integrated appearance guidance ensures temporal coherence.
What are the Key Features?
Key features include fine-grained holistic controllability, multi-scale adaptability (portrait to full-body), long-term temporal coherence, identity preservation, high fidelity, audio-driven animation support, partial motion transfer, and shape-aware adaptation.
Can I see Examples?
Yes, please check the Video Demonstration and the examples provided in the Features and Comparison sections.