DreamActor-H1
DreamActor-H1 transforms a single human image and product photo into a high-fidelity, motion-rich demonstration video. Powered by Motion-designed Diffusion Transformers.
Generated Result
Redefining E-Commerce Video
Generating realistic human-product interaction videos has historically been a challenge. Traditional methods often distort human faces or warp product logos.
DreamActor-H1 solves this by integrating a Diffusion Transformer (DiT) with a novel reference injection mechanism. This ensures that the texture of your product and the identity of your model remain perfectly consistent throughout the video, while executing natural, physics-aware hand gestures.
- High-Fidelity Identity Preservation
- Precise Hand-Product Alignment
- Robust 3D Consistency
Under the Hood
A hybrid architecture combining VLM descriptors, 3D Pose Estimation, and DiT Video Generation.
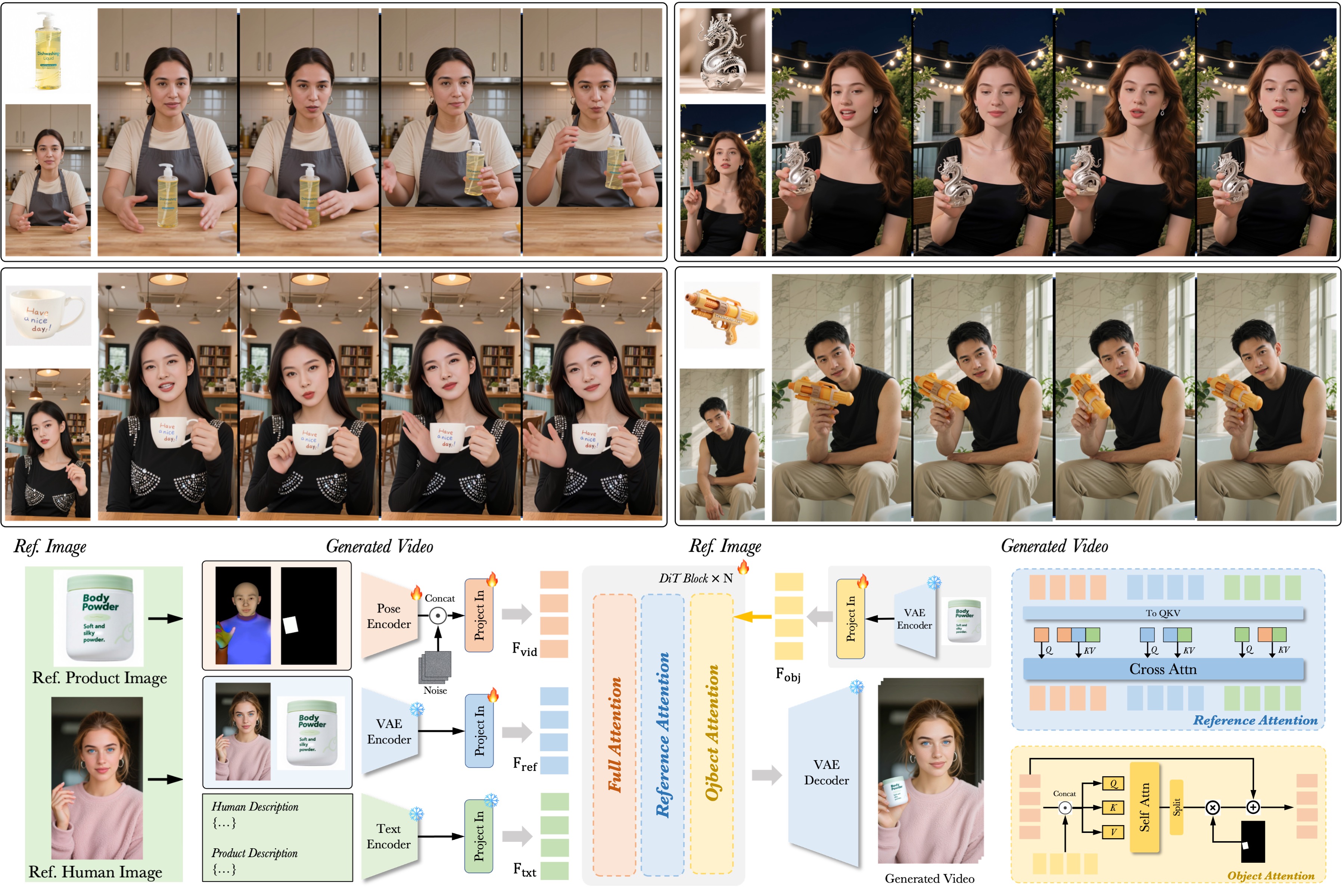
1. Input Analysis
Vision-Language Models describe the scene, while Pose Estimation extracts motion skeletons and bounding boxes.
2. Reference Injection
Human and product images are encoded via VAE and injected into the DiT using masked cross-attention.
3. DiT Generation
The Diffusion Transformer synthesizes the video frame-by-frame, ensuring temporal consistency and realism.
Versatile Generation
Works across various product categories and human subjects.
More Examples
Swipe to explore different identities and motions.
Ablation Study
Demonstrating the necessity of our text-input module and object-attention mechanisms. Without these components, the model struggles to maintain product fidelity.