DreamActor-H1
DreamActor-H1 将单张人物图像和产品照片转化为高保真、运动丰富的演示视频。由运动设计的扩散变换器驱动。
生成结果
重新定义电子商务视频
生成逼真的人与产品交互视频一直是一个挑战。传统方法通常会扭曲人脸或产品标志。
DreamActor-H1 通过集成 扩散变换器 (DiT) 和新颖的参考注入机制解决了这个问题。这确保了您的产品纹理和模型的身份在整个视频中保持完美一致,同时执行自然、符合物理规律的手势。
- 高保真度身份保持
- 精准的手与产品对齐
- 强大的 3D 一致性
与 SOTA 模型的比较
技术揭秘
结合了 VLM 描述符、3D 姿势估计和 DiT 视频生成的混合架构。
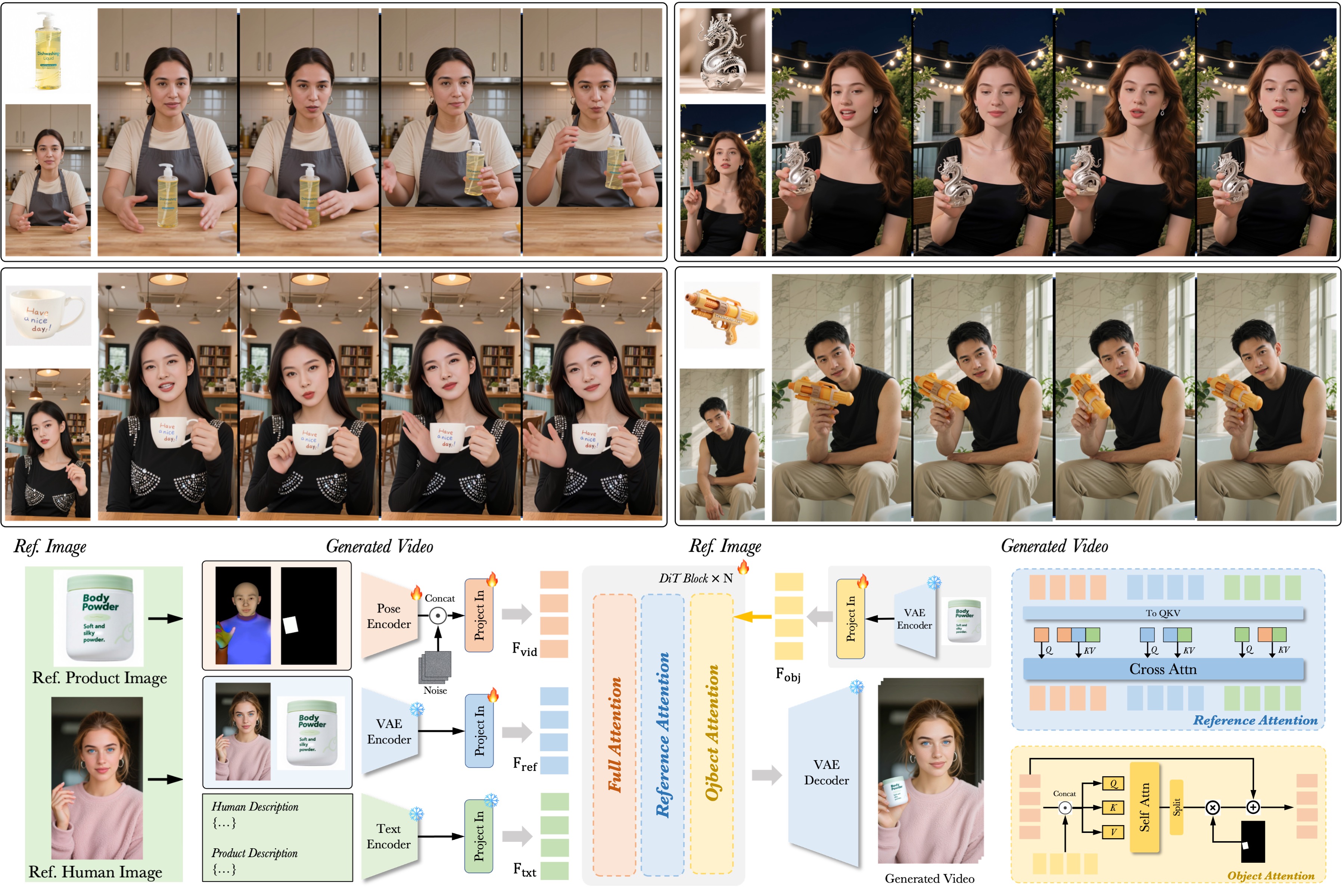
1. 输入分析
视觉-语言模型描述场景,而姿势估计提取运动骨架和边界框。
2. 参考注入
人物和产品图像通过 VAE 编码,并使用掩码交叉注意力注入到 DiT 中。
3. DiT 生成
扩散变换器逐帧合成视频,确保时间一致性和真实感。
多功能生成
适用于各种产品类别和人物主体。
showcase.videoTitles['02.mp4']
showcase.videoTitles['05.mp4']
showcase.videoTitles['35.mp4']
showcase.videoTitles['06.mp4']
showcase.videoTitles['08.mp4']
showcase.videoTitles['14.mp4']
更多示例
滑动查看不同身份和动作。
消融实验
展示我们的文本输入模块和对象注意力机制的必要性。没有这些组件,模型难以保持产品保真度。