DreamActor-M1 概述
最近基于图像的人类动画的进步改善了身体和面部运动合成,但在实现细粒度控制、多尺度适应性和长期一致性方面仍然存在挑战。这些限制会影响动画的表现力和稳健性。
DreamActor-M1 特性:
- 运动引导 一种混合控制机制,结合了隐式面部表示、3D 头部球体和 3D 身体骨架,以确保稳健且富有表现力的面部和身体运动。
- 尺度适应性 一种渐进式训练策略,结合多分辨率数据来管理各种身体姿势和图像尺度(从肖像到全身视图)。
- 外观引导 来自连续帧的运动模式和视觉参考有助于保持长期时间一致性,特别是对于复杂运动期间的未见区域。
方法概述
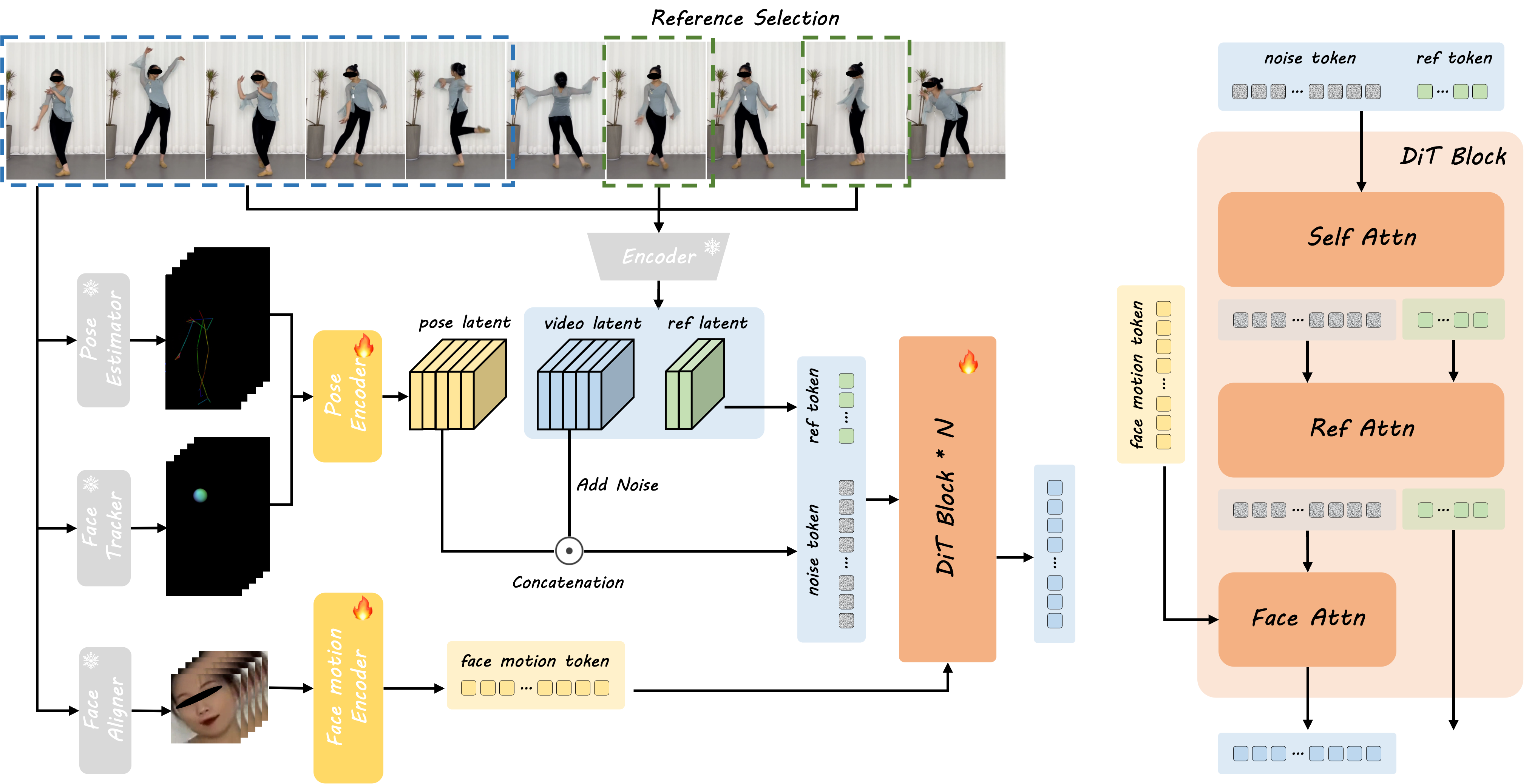
- 1参考图像处理 该框架插值起始参考图像并从驱动帧中提取身体骨架和头部球体。
- 2姿势编码 提取的骨架数据使用姿势编码器编码为姿势潜在向量。
- 3潜在向量组合 姿势潜在向量与通过 3D VAE 编码获得的噪声视频潜在向量相结合。
- 4面部表情编码 单独的面部运动编码器捕获隐式面部表示。
- 5多尺度训练 从视频中采样的参考图像提供额外的外观细节,确保真实性和稳健性。
- 6DiT 处理 DiT 模型使用面部注意力、自注意力和参考注意力来优化视频潜在向量。
- 7监督与精炼 去噪后的视频潜在向量与编码后的视频潜在向量进行监督,确保高质量输出。
视频演示
摘要
DreamActor-M1 是一个基于扩散变换器(DiT)的人类动画框架,解决了现有方法中的关键限制。我们的方法具有三大创新:(1) 混合运动引导,结合面部表情、3D 头部建模和身体骨架,实现精确控制,同时保持身份特征;(2) 多尺度适应性,通过渐进式训练支持从肖像到全身动画的所有内容;(3) 通过整合连续运动模式和视觉参考来增强时间一致性。通过广泛测试,DreamActor-M1 在生成跨不同规模和场景的一致、高质量动画方面表现出卓越的性能。
主要功能
多样性
我们的方法对各种角色和运动风格都具有稳健性。
可控性和稳健性
- 可扩展到音频驱动的面部动画,提供多种语言的唇形同步结果。
- 互补的视觉引导确保了更好的时间一致性,特别是对于参考中未观察到的人体姿势。
- 支持仅迁移部分运动,例如面部表情和头部动作。
- 通过骨长调整技术适应形状感知动画。
- 支持在不同头部姿势方向下生成结果。
与 SOTA 方法的比较
我们的方法生成的动画具有细粒度运动、身份特征保持、时间一致性和高保真度。
姿势迁移
肖像动画
最新更新与研究
Gambo AI Games 详细介绍
Gambo 是一个 AI 驱动的游戏开发平台,被称为"世界首个 Game Vibe Coding Agent"。它通过自然语言指令,将创意快速生成可玩的游戏原型,并自动创建游戏所需的各种资产。
Meta SAM 3D:从一张图片直接生成 3D 模型的开源突破
Meta 最新发布的 SAM 3D 能够从单张图像中自动分割目标,并直接生成完整的 3D 模型(包含几何和纹理)。速度快、精度高、流程简单,是 3D 内容生成领域的一次突破式进展。
Google Antigravity 深度研究:Gemini 3 时代的"Agent-first 开发平台"
2025 年 11 月 18 日,Google 正式发布 Antigravity——一个真正意义上的 Agent-first AI 开发平台 / AI IDE。它不仅是"会写代码的助手",更是能自动规划、执行、验证整套任务的 AI 工作者。
常见问题
DreamActor-M1 是什么?
DreamActor-M1 是一个基于扩散变换器(DiT)的框架,旨在利用混合引导实现整体、富有表现力且稳健的人类图像动画。它可以根据参考图像生成逼真的视频,模仿来自不同规模驱动视频的人类行为。
DreamActor-M1 如何工作?
它使用带有混合控制信号(隐式面部表示、3D 头部球体、3D 身体骨架)的 DiT 模型进行运动引导。渐进式训练策略用于处理不同规模,集成外观引导则确保了时间一致性。
主要功能有哪些?
主要功能包括细粒度的整体可控性、多尺度适应性(肖像到全身)、长期时间一致性、身份特征保持、高保真度、音频驱动动画支持、局部运动迁移和形状感知适应。
我可以查看示例吗?
可以,请查看视频演示以及功能和比较部分中提供的示例。